Najpierw trzeba zdefiniować problem, następnie zgromadzić jak najwięcej przydatnych informacji (przeszukiwanie baz danych – przez np. Azure, tłumacz Microsoft, konwersję treści pisanej i graficznej i wideo na algorytmy – nie znam takiego narzędzia). Następnie należy uporządkować dane. Zaproponować koncepcje rozwiązań. Przenieść je do map myśli. Powinno się stworzyć narzędzia do wizualizacji rozwiązań. Przydatne będzie pokazanie różnych wariantów danego projektu po zmianie dowolnego parametru (taką wizualizację graficzną danych może zapewnić – np. Język Luna ). Jak działać może dynamiczne projektowanie można zobaczyć przy planowaniu nowego centrum MIT w filmie Marcina Prokopa z TVN “Człowiek przyszłości”
Wyobraźnię przestrzenną i projektową może zapewnić rzeczywistość wirtualna i rozszerzona z dostępem do wielu danych i wizualnych modeli badanych pomysłów).
Już widzę menadżera w małej firmie w okularach do wirtualnej rzeczywistości, który planuje swój nowy projekt w firmie. Dzięki algorytmom GDMMiA uniknie wielu błędów i szybko podejmie najlepsze decyzję decyzję (doradcami będzie cała społeczność map algorytmów).
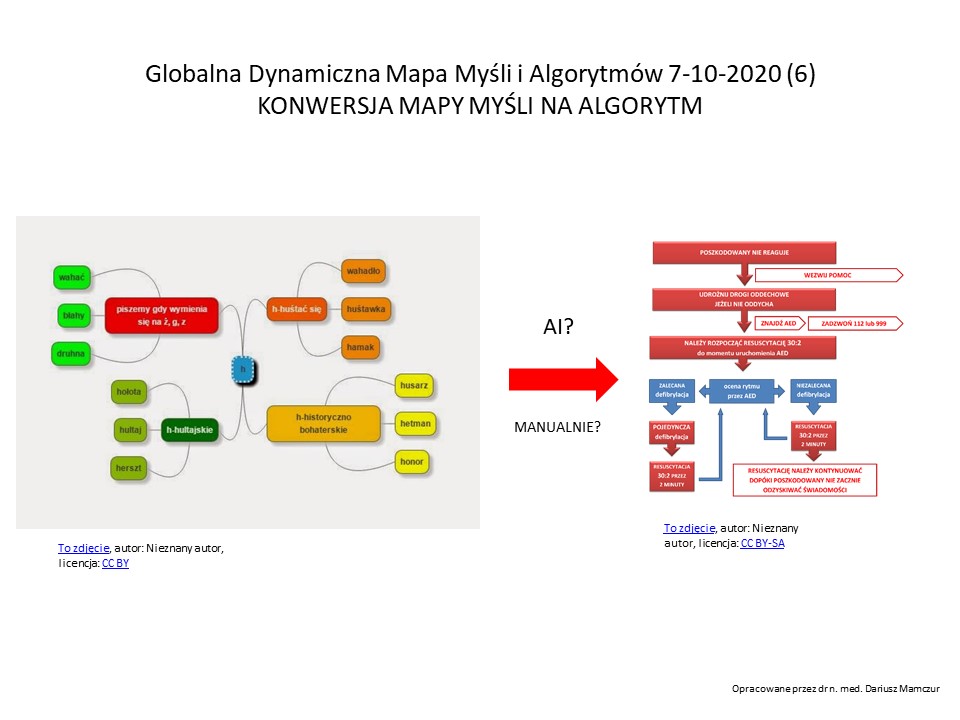
Wyzwaniem może być stworzenie programu, który od razu przenosił wizualizacje i koncepcje do map myśli, a z nich do algorytmów). Myślę, że zespół Azure dałby sobie z tym radę?
Ostatnio próbowałem zainteresować tematem Globalnej Dynamicznej Mapy Myśli i Algorytmów (GDMMiA) polskich informatyków. Niestety są tak zajęci, że może zajmą się tym w grudniu (wtedy chyba tylko po to, żeby przeprowadzić wywiad 🙂
Postanowiłem poszukać pomocy poza Polską. Okazuje się, że firma Microsoft ma świetną bazę do realizacji mojego projektu. Niestety nie ma bezpośredniego kontaktu do działu usług poznawczych i sztucznej inteligencji (czekam na odpowiedź).
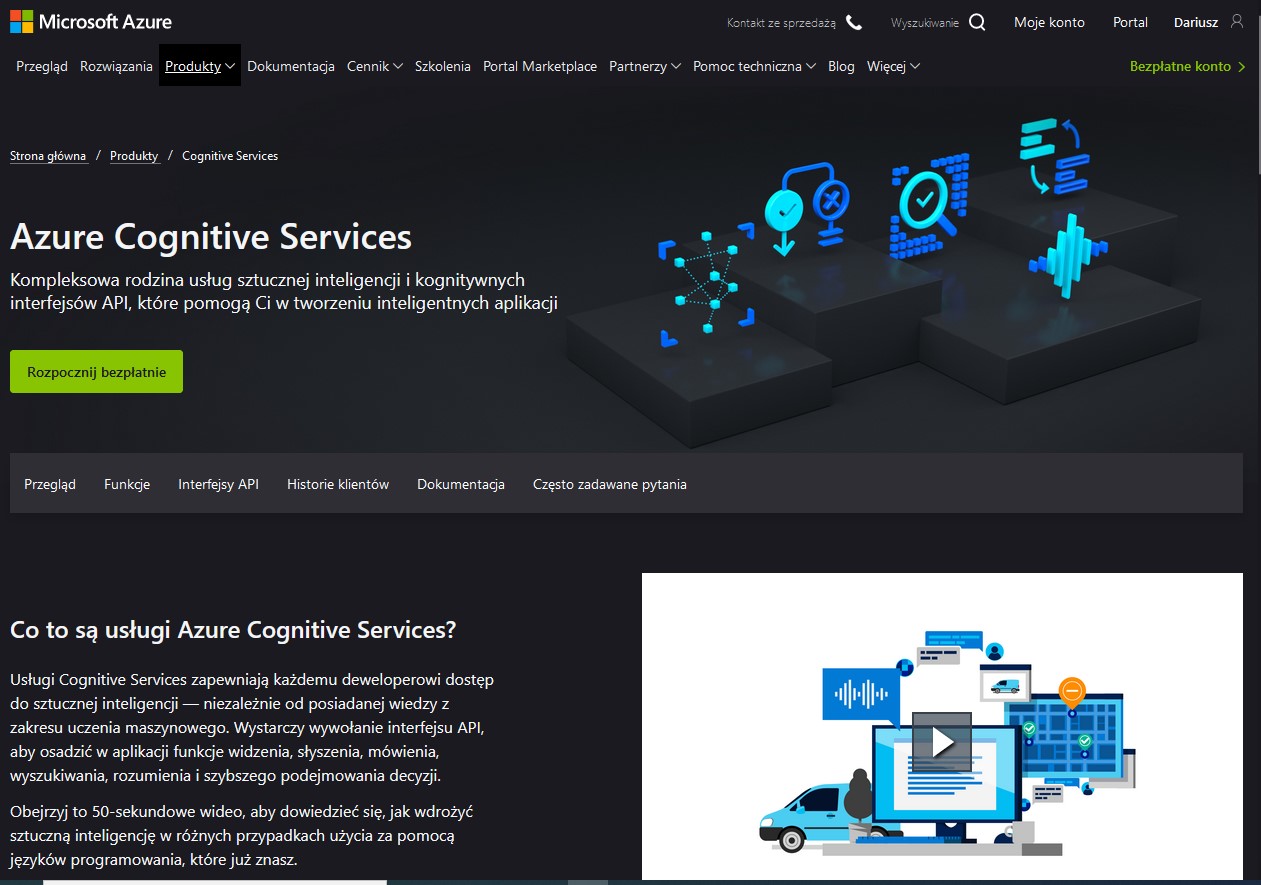
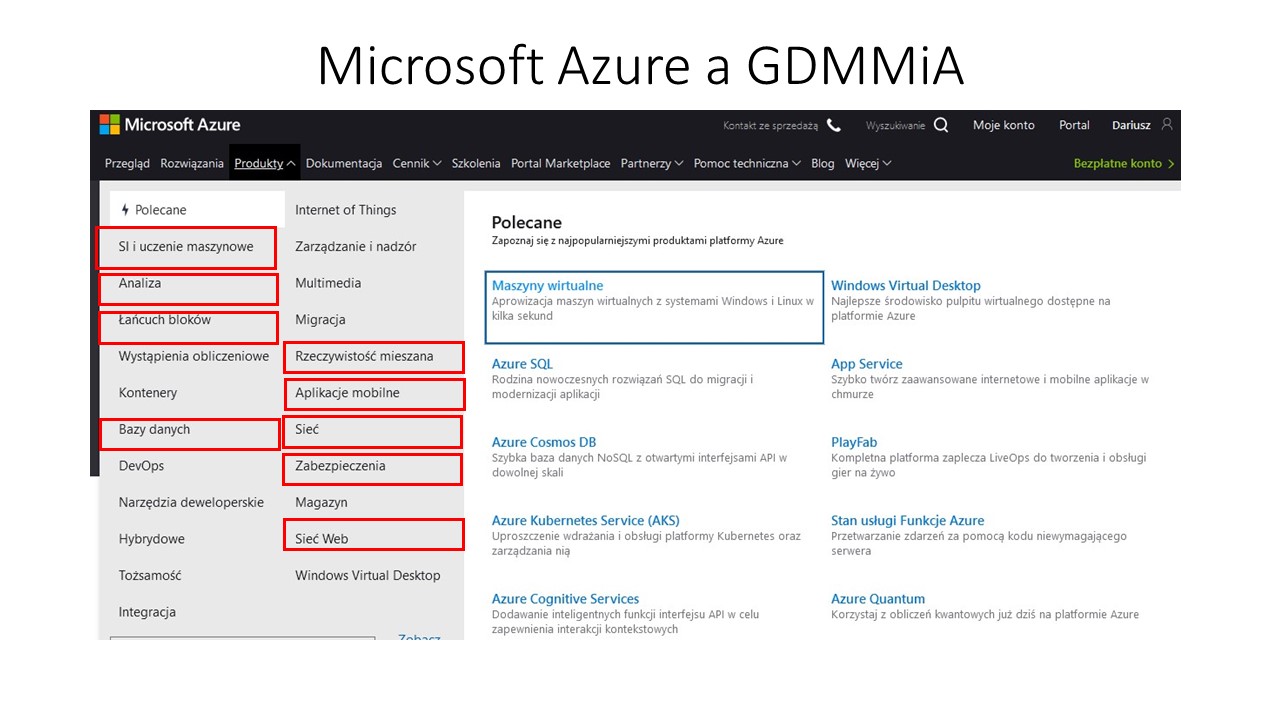
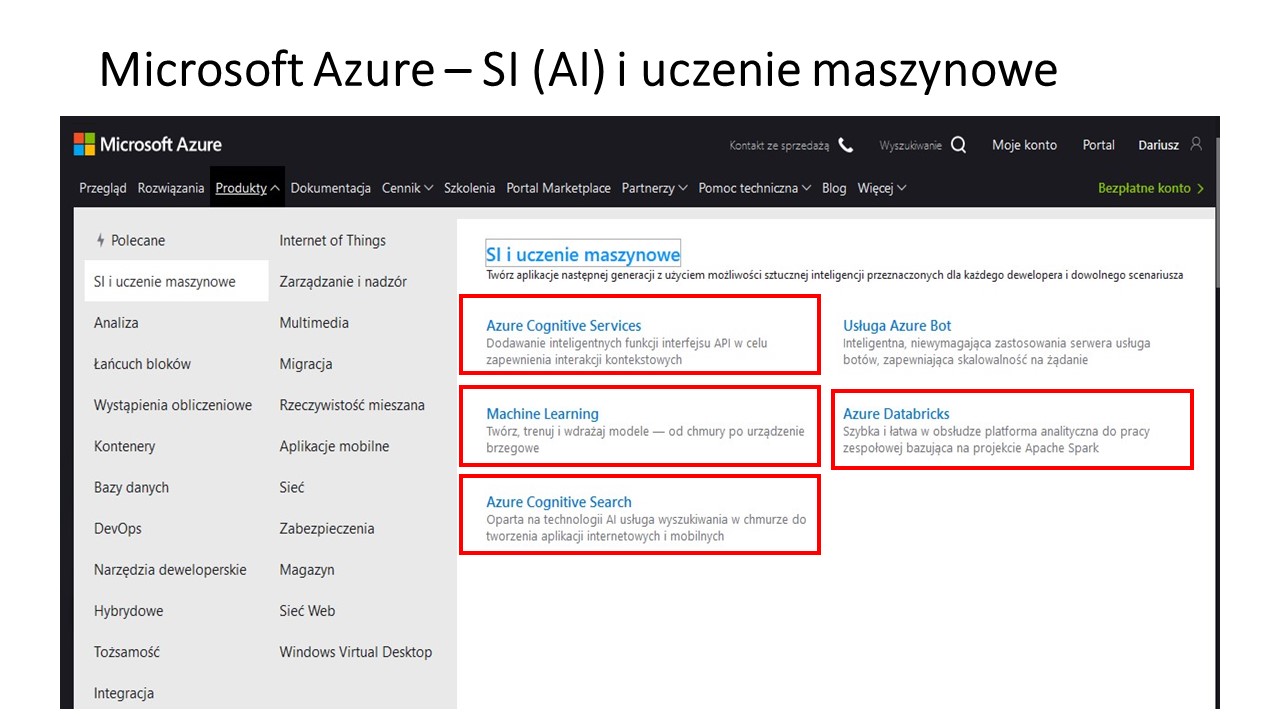
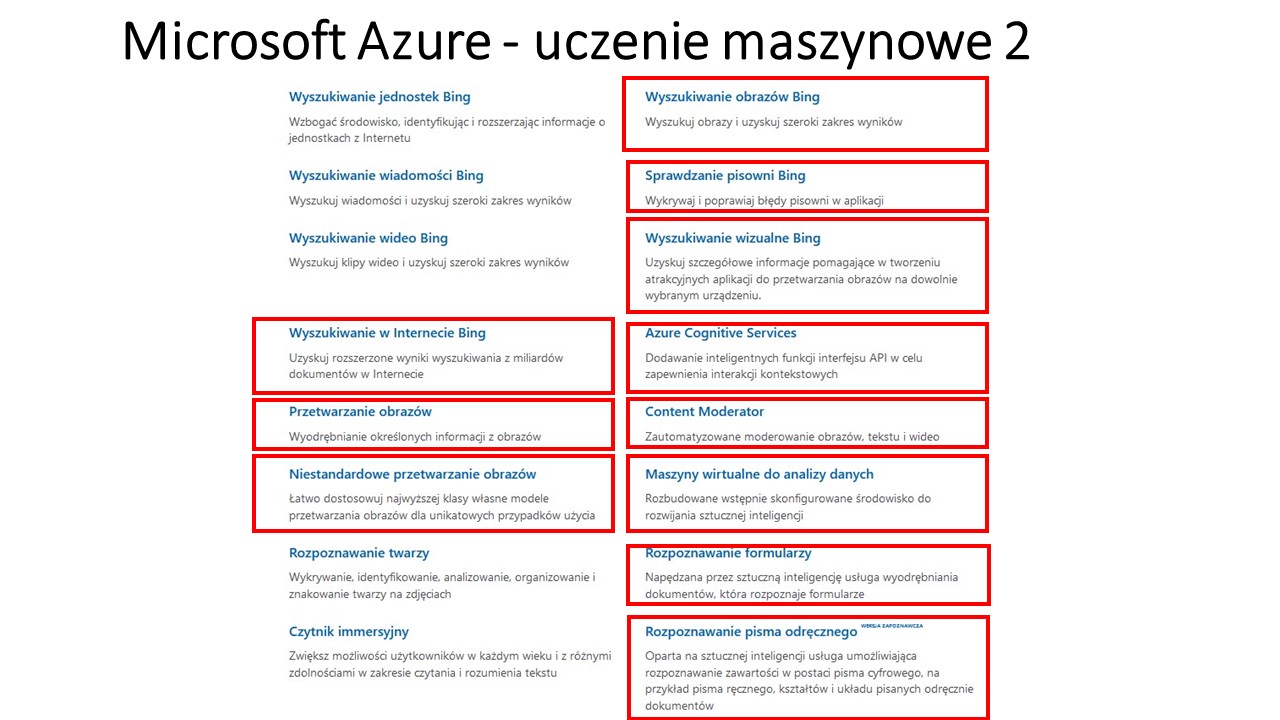
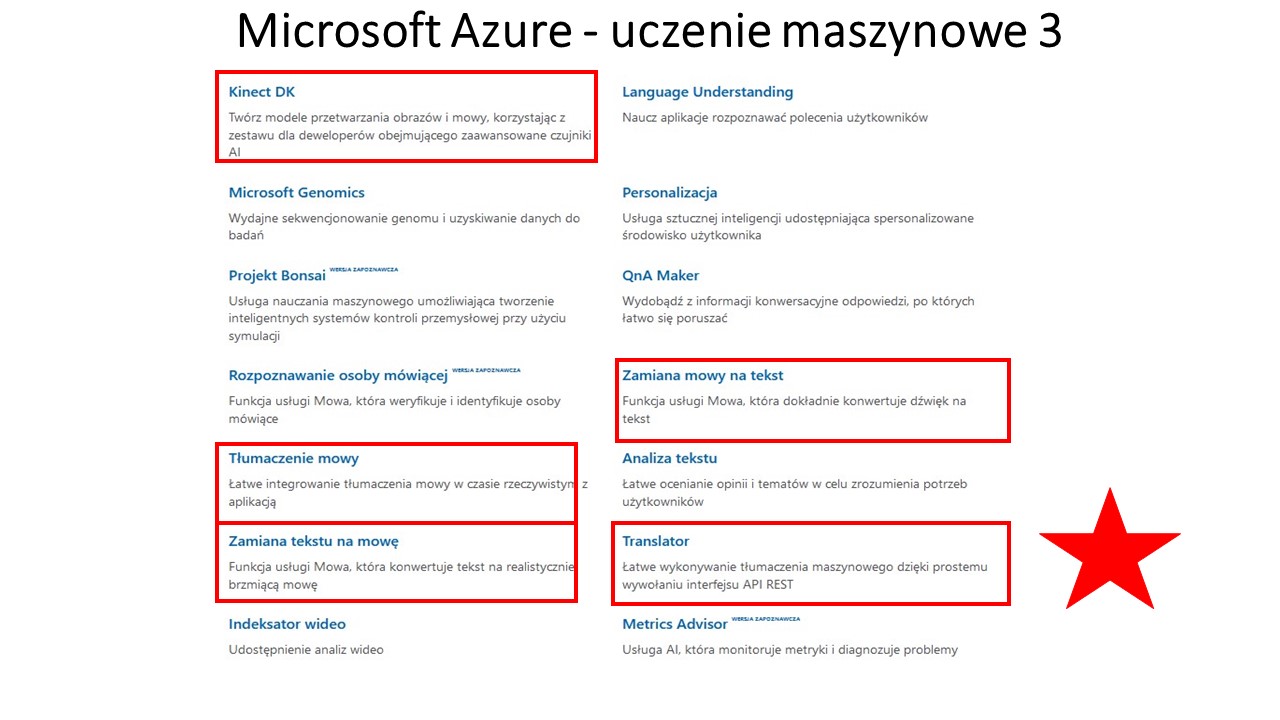
Platformą do świadczenia usług dla procesów poznawczych jest Cognitive Services w Microsoft Azure.
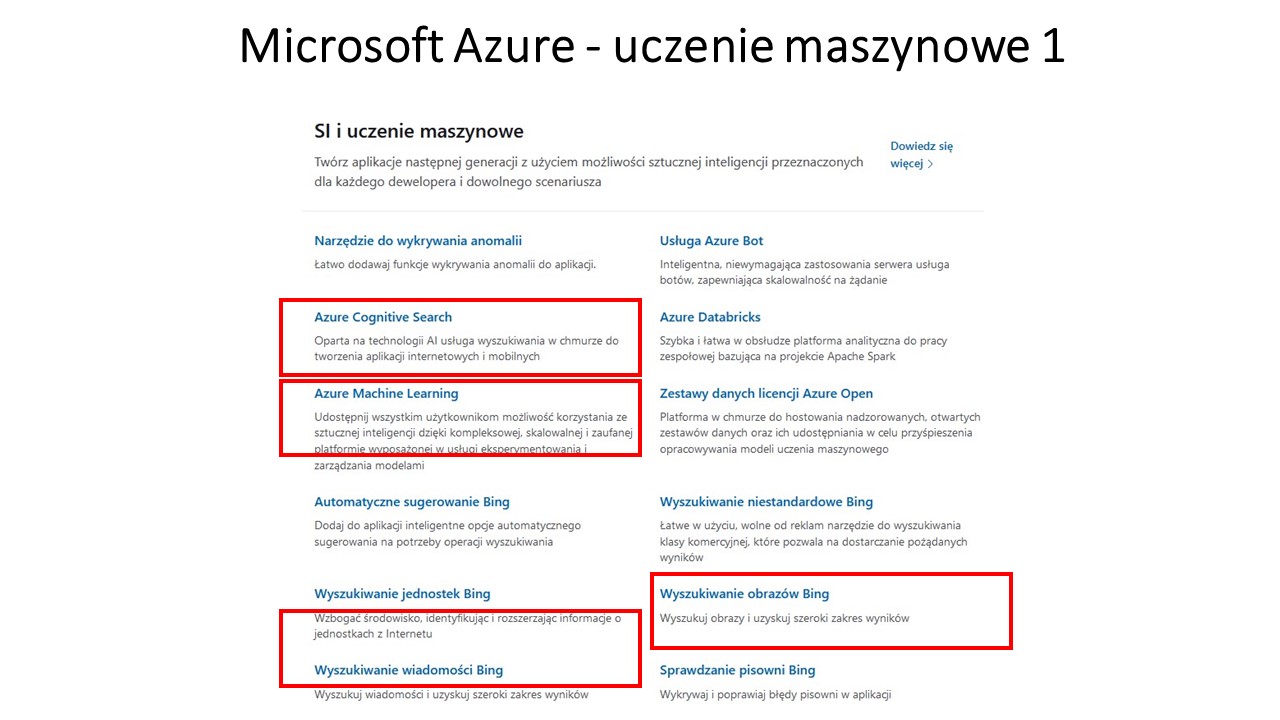
sztuczną inteligencję, tłumacz 70 języków w systemie sieci neuronowych, transkrypcja mowy na tekst, analiza wideo (być może pozwoli na tworzenie algorytmów z filmów), uczenie maszynowe (do tworzenia mapy algorytmów), analizy danych pod kątem map algorytów – w tym ranking najlepszych, łańcuch bloków (block chain – pozwoli na bezpieczną strukturę map i zapewni prawa autorskie – przydatne w monetyzacji projektu oraz zadba chronologię dodawanych algorytmów), bazy danych – będą pożywka dla algorytmów), rzeczywistość mieszana umożliwi łatwiejsza komunikację oraz tworzenie wirtualnych map myśli), aplikacje mobilne – aplikacja map dostępna na urządzeniach mobilnych, sieć www – obsługa map w całym świecie, wyszukiwanie obrazem (szukamy graficznych map myśli i algorytmów, które konwertujemy na algorytmy i dodamy do GDMMiA – na razie nie znam narzędzia na świecie do takiej konwersji!??? – technicznie nie jest to chyba zbyt skomplikowane z np z do JAVA).
“In the last five years,” Huang said, “we have achieved five major human parities: in speech recognition, in machine translation, in conversational question answering, in machine reading comprehension, and in 2020, in spite of COVID-19, we got the image captioning human parity.”
Postęp w słownym opisie obrazów jest olbrzymi. Narzędzie jest wprowadzane do aplikacji Office. Podejmuje się próby natychmiastowego opisywania obrazów rejestrowanych przez oko kamery. Daje to możliwość mówienia osobie niewidzącej, co znajduje się przed pacjentem!
Dla GDMMiA powstaje szansa na zautomatyzowanie przenoszenia np. map myśli lub algorytmów znajdujących się w plikach graficznych (np. jpg) ale także na filmach (np. w “stop klatce”
Saqib Shaikh, a software engineering manager with Microsoft’s AI platform group in Redmond.
Dla mojego projektu sukcesem byłoby, aby te algorytmy na tym zdjęciu narysowane na z tyłu na tablicy znalazły się w wersji cyfrowej w formacie algorytmu. W ilu firmach brakuje takiego narzędzia w tworzeniu projektów!
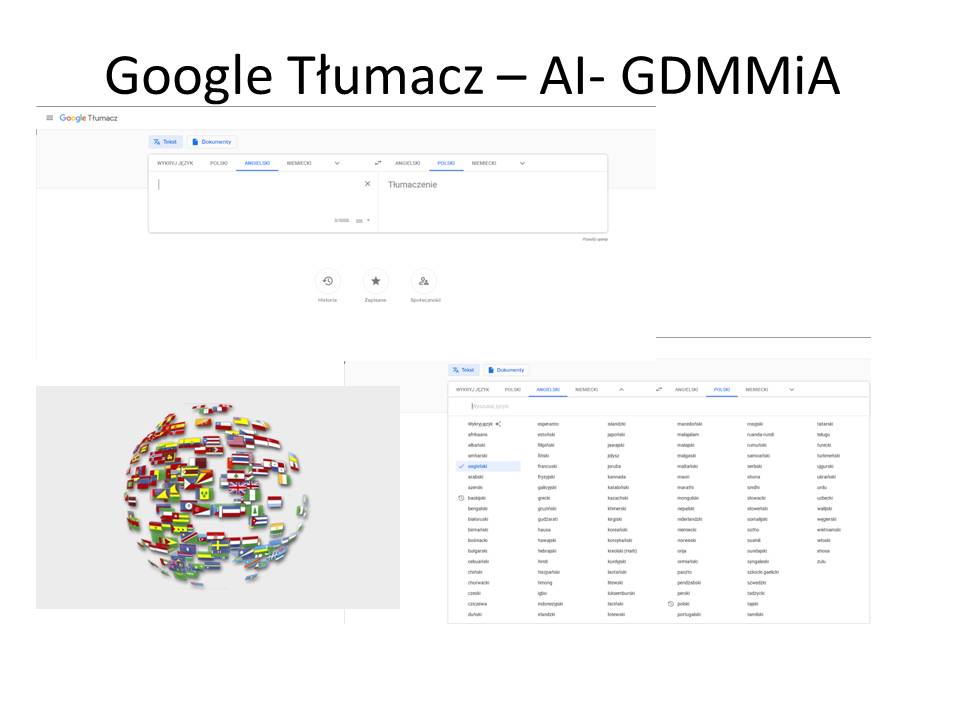
Budowanie Globalnej Dynamicznej Mapy Myśli i Algorytmów (GDMMiA) będzie wymagało jednego języka do tworzenia treści map. Może to być wymyślony język widoczny tylko dla komputerów lub np. język angielski. Niezależnie od tego powinno się móc stworzyć inteligentny interfejs automatycznie tłumaczący wprowadzane treści na wszystkie języki świata. Wspaniałym wzorcem może być oparty na sztucznej inteligencji Tłumacz Google. Narzędzie cały czas się uczy coraz to nowych słów i związków frazeologicznych. Taki program powinien wejść w skład “silnika” GDMMiA.
Aplikacja opiera się na sieciach neuronowych, paradygmatach bazujących na przepisywaniu oraz mechanizmu przetwarzania na urządzeniu, ponadto z nowością jest implementacja tzw. architektury hybrydowej.
(“Co to są usługi Azure Cognitive Services? -Usługi Cognitive Services zapewniają każdemu deweloperowi dostęp do sztucznej inteligencji — niezależnie od posiadanej wiedzy z zakresu uczenia maszynowego. Wystarczy wywołanie interfejsu API, aby osadzić w aplikacji funkcje widzenia, słyszenia, mówienia, wyszukiwania, rozumienia i szybszego podejmowania decyzji.”)
Także Microsoft wprowadza tłumaczenie maszynoweMicrosoft Translator (Translacja Maszyn Neuronowych+ True text +zmiana tekstu na mowę i mowy na tekst+ tłumaczenie mowy – dobry opis i demo procedur)) dostępne w pakiecie Office (70 języków – czyli mniej niż Tłumacz Google, pozostałe języki są tłumaczone metodą SMT) (zaznacz tekst – naciśnij prawym klawisz – przetłumacz- wybierz język-enter)
Ciekawą opcją (starszą) jest statystyczne tłumaczenie maszynowe Bing Microsoft Translator pojedynczych słów, który wykrywa język źródłowy i tłumaczy n żądany język
Postęp technologiczny otwiera nam nowe możliwości rozwiązań, o których kilka lat temu nam się nie śniło. To tak jak wejść do korytarza, a w nim otwierają się kolejne drzwi ku naszym marzeniom. Jeśli nie będziemy się uczyć, nie zobaczymy nowych możliwości.
Gdy tworzyłem koncepcję Globalnej Dynamicznej Mapy Myśli i Algorytmów (GDMMiA) miałem kilka problemów strategicznych, jak można przekształcić zmysły, myśli człowieka, wiedzę zapisaną w książkach, nośnikach cyfrowych, obrazach, filmach na algorytmy. Sztuczna inteligencja (AI) potrzebuje algorytmów, do konstrukcji nowych rozwiązań technologicznych w oparciu o listy “to do”. Algorytm powstaje z myśli człowieka. Człowiek zaś ma kreatywne myślenie, ale oparte na swoim doświadczeniu i wiedzy, czyli danych napływających z otaczającego nas świata. Niezależnie od naszego myślenia maszyny komputerowe będą mogły tworzyć własne algorytmy, pod warunkiem dostarczenia im dużej ilości danych (big data). Przyzwyczailiśmy się do danych zapisanych w arkuszach kalkulacyjnych i treści pisanej. Jednak najbardziej “dano-chłonne” są obrazy, filmy, dźwięki. Tu jest skarbnica danych.
Jeżeli maszyny są w stanie wychwytywać komendy wydawane głosem podczas rozpoznawania mowy (jeden z pierwszych zajmujący się tym tematem to Kai-Fu Lee) oraz rozpoznawania prostych, statycznych obrazów (zajmuje się tym m. in. Google – Kuba Piwowar z Google – 2018 r ), to może z czasem będą w stanie same w stanie tworzyć algorytmy z danych dostarczanych im w formie audio (np. podcast), obrazów czy filmów.
Wyobraźmy sobie, że filmujemy wykonywanie jakiejś czynności. Następnie komputer analizuje audio z obrazem i tworzy algorytm czynności znajdujących się na filmie. Może wychwyci więcej niż człowiek? Stworzy niekonwencjonalne rozwiązania, będzie świetnym narzędziem dydaktycznym, czy projektowym.
Dlatego traktuję obecne bania nad rozpoznawaniem mowy i dźwięku jako pionierskie abecadło sztucznej inteligencji (przedszkole AI). Czas na szkołę i studia :). Patrzmy za horyzont! (Look beyond the horizon).
Co z innymi zmysłami – dotykiem, smakiem, zapachem? To też może być algorytmem.
Wyobraźmy sobie cały przemysł kosmetyczny, kulinarny, medycynę wsparte o takie urządzenia.
Co lekarz ma wspólnego ze sztuczną inteligencją? Niedługo już nic, jak go zastąpi w ciągu najbliższych 15 lat 🙁
Trzeba znaleźć miejsce w medycynie dla AI i dla lekarza. Na początku będę współpracować, potem czynnik ludzki zejdzie na drugi plan.
Dlatego interesuje się w chwili obecnej uczeniem maszynowym, uczeniem głębokim i sieciami neuronowymi.. Podziwiam pasjonatów algorytmów, takich Vladimir Alekseichenko (oryginał nazwiska to chyba Владимир Алексейченко – czyli polska i rosyjska wymowa Władimir Aleksiejczenko) (podcaster i programista uczenia maszynowego oraz NLP – przetwarzanie języka naturalnego), ale liczę także na ich zainteresowanie w rozwijaniu sztucznej inteligencji (polecam polską stronę Sztuczna inteligencja) na bazie GDMMiA.
W dniu 28.09.2024 w TVN24, w cyklu “Ewa Ewart poleca” ukazał się pierwszy odcinek filmu “Epoka sztucznej inteligencji” (oryginalny tytuł to “In the age of AI”.) (Artificial intelligence)
Polecam do obejrzenia
Sztuczna inteligencja AI = SI) – zalety i zagrożenia (totalny nadzór nad społeczeństwem, zniknie około 50% zawodów w ciągu 15 lat (szczególnie umysłowych – np. analitycy), utrata miejsc pracy (np. w USA ok. 300 tys. kierowców ciężarówek), podział świata na dwa bloki – Chiny i USA. Chiny obudziły się po przegranej w 2016 r mistrza gry GO Ke Jie z AlphaGo firmy Google) (podobno w GO jest więcej kombinacji strategicznych niż atomów we wszechświecie- gra jest dumą cywilizacji dalekiego wschodu) z komputerem IBM Watson. Komputer jest silniejszy od człowieka. Władze Chin w 2017 r. ogłosiły, że chcą być do 2030 światowym liderem AI (nie naśladowcą!) Już działa rządowe wsparcie – w planie budowa miasta wielkości Chicago z transportem zarządzanym przez AI. Szeroko wdraża się np. rozpoznawanie twarzy, transport bez kierowców), już maja wielu firm AI z grupy tzw. Unicorn = warunkiem jest miliardowy dochód). Chiny przeskoczyły etap kart kredytowych – w sklepach płaci się “twarzą” (aplikacje rozpoznawania twarzy).
Chiny są największą bazą danych, a nią karmi się AI: “Dane to ropa, a Chiny są na tym polu Arabia Saudyjską” KAI-FU LEE (Sinovation Venture) (w wieku 31 lat opracował program rozpoznawania mowy do sterowania komputerem). “Kilka tysięcy współpracujących ze sobą chińskich przedsiębiorców pokona każdego przedsiębiorcę na świecie”
W historii było tylko kilka istotnych wynalazków: maszyna parowa, elektryczność i komputer. Teraz będzie to AI.
AI w medycynie – uczenie maszynowe i uczenie głębokie (deep learning) w analizie zdjęć rentgenowskich jako profilaktyka raka piersi (W USA umiera na te chorobę około 40 tys. kobiet rocznie). Wywiady z pracownikami MIT z Bostonu w USA (Massachusetts Institute of Technology Bostonie. Na MIT (Massachusetts Institute of Technology) pracuje Aleksandra Przegalińska – z Akademii Leona Koźmińskiego – z wywiadu Marcina Prokopa z TVN -“Człowiek przyszłości” – polecam). Program profilaktyki raka piersi poprzez głębokie uczenia maszynowego w MIT prowadzi z dr Connie Lee (?) m.in. profesor Regina Barzilay
Rozwijająca się w ostatnim czasie w bardzo w szybkim tempie sztuczna inteligencja wymaga dostarczani jej dużej ilości algorytmów. Z czasem będzie możliwe szerokie stosowanie uczenia maszynowego, które te algorytmy będzie tworzyć samodzielnie. Zalążek takich programów zależy jednak od wiedzy twórców danych innowacji. To oni tworzą algorytm – czasem lepszy, czasem gorszy. Potem, owszem, można przeprowadzać komputerowe badania modelowe, ale badamy tylko koncepcję jednego zespołu. A co by było, gdyby mogli oni skorzystać z już zweryfikowanych algorytmów z innej części świata? Ilu błędów by uniknięto? Jakich pomysłów nie byłoby w burzach mózgów ich zespołów, a są w GMMiA ? Na następnym etapie baza algorytmów byłaby “pożywką” dla komputerów, które dzięki sztucznej inteligencji (w tym głębokiego i maszynowego uczenia) mogłaby tworzyć nowy, bardziej kreatywny algorytm, o którym ludziom się nawet nie śniło (tak jak rewelacyjny ruch nr 37 w grze GO podczas meczu Lee Sedol z komputerem Google – AlphaGo).
Uważam, że koncepcja Globalnej Dynamicznej Mapy Myśli i Algorytmów (GDMMiA) mogłaby się sprawdzić w tym procesie.
Mapy algorytmów w etapie wstępnym można tworzyć ręcznie (przez ogólnoświatową społeczność – zalążkiem ich byłyby mapy myśli), można też zaimportować pliki graficzne map myśli z dotychczasowych książek, publikacji internetowych ( potrzebny by był program konwertujący grafikę do map algorytmów – nie znalazłem nigdzie takiej aplikacji) – z nich powstaną listy “to do” dla prototypów wynalazków.
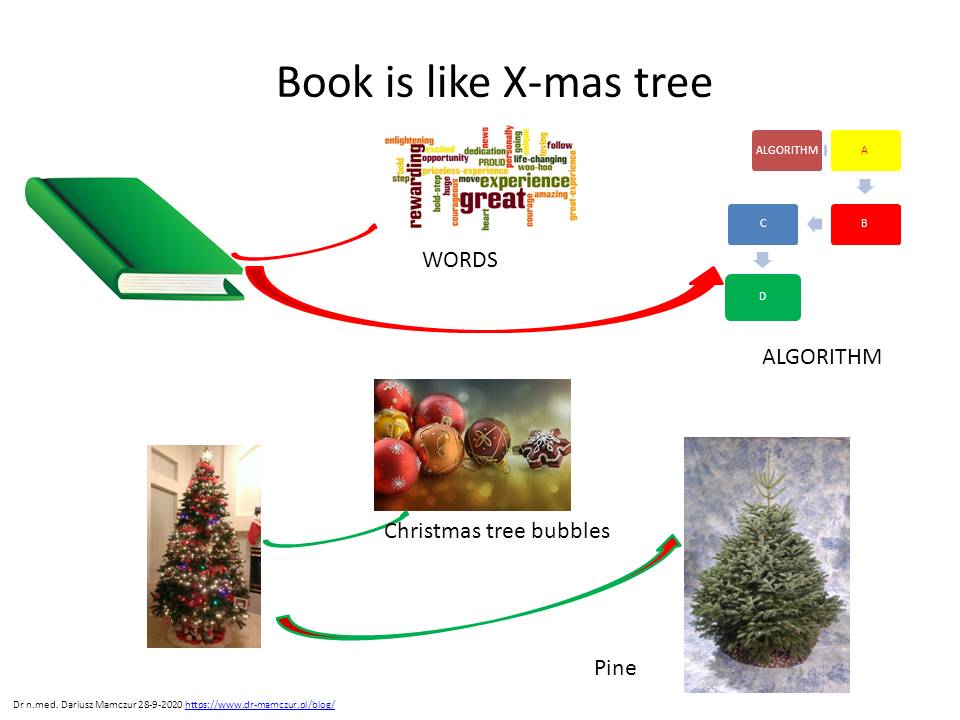
Problemem jest jednak jak przełożyć dotychczasową wiedzę tekstową na algorytmy. Myślę, że z pomocą może przyjść uczenie maszynowe pracujące na big data. Być może wyszukiwarki semantyczne mogłyby wchodzić w skład silnika takiej aplikacji. Narzędzie to po analizie tekstu, stworzy algorytm podsumowujący treść danej publikacji. Algorytmu się nie oszuka!. Jeśli jest on taki sam jak w innej książce opisującej innymi słowami tę samą procedurę – od razu będzie widać, że autor książki nie wniósł nic nowego dla ludzkości (zobaczmy ile jest poradników sprzedających te same porady, ale tylko innymi słowami. Ile cennego czasu tracimy na czytanie tego samego pod innym tytułem – i to tego samego autora). Z książkami jest jak z choinką. Jest algorytm ubrany w słowa, tak jak sosna ubrana w bąbki.
Choinkę możemy ubierać w różne bąbki, ale zawsze będzie to ta sama choinka.
Ponadto uczenie maszynowe pozwoliłoby na ciągłą, zautomatyzowaną (dynamiczną) aktualizację bazy, przy współistniejącej dotychczas formie werbalnej i graficznej przedstawiania swoich myśli (książki, strony www, grafiki, zdjęcia).
To jest zupełnie inny silnik niż Google!!
Prawdopodobnie nikt takiego nie ma!!.
To nie internauta w tym narzędziu przeszukuje bazy danych. On dostaje już gotowe zaktualizowane rozwiązania (wiedzę – ekspertyzę) na swoje zapytanie. Zostaje mu jedynie jej przeanalizowanie i zaimplementowanie jej dla swoich potrzeb i podzielenie się zdobytą w ten sposób wiedzą nią z innymi (utopia – czy potrzeba czasu). Rzetelność, stabilność systemu i prawa autorskie mógłby zagwarantować blockchain.
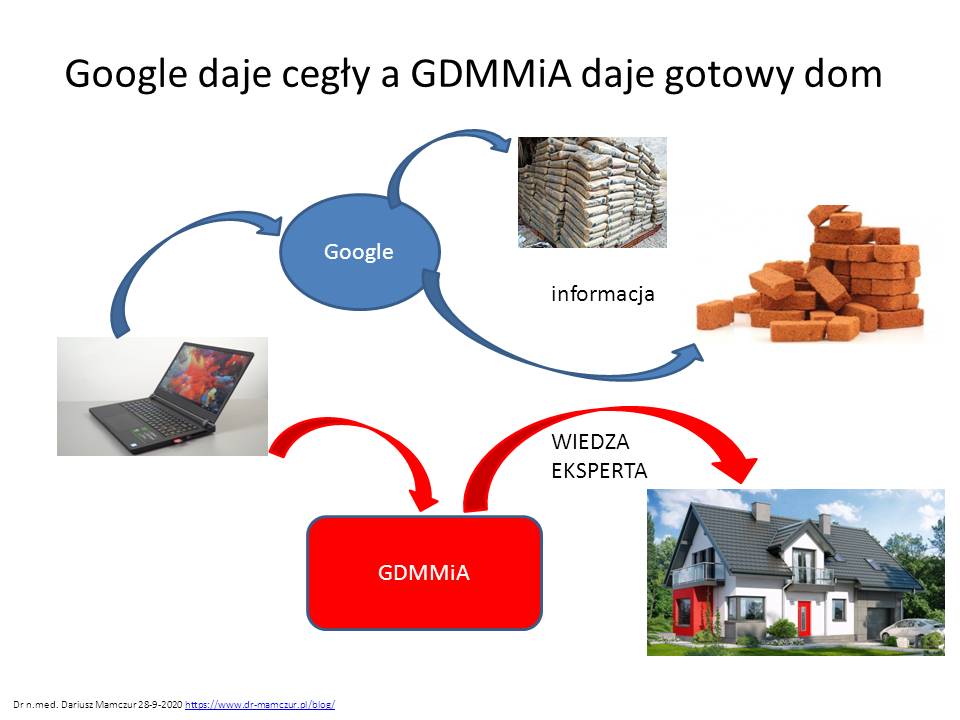
Google daje nam cegły i cement (tylko informacje – WAT?) , mój silnik od razu gotowy dom (daje wiedzę eksperta – HOW!). Czyli bardziej zaawansowane narzędzie niż robione “ręcznie” WIKI-HOW.
Dlatego uważam, że w najbliższym czasie w realizacji GDMMiA najcenniejsze może być stworzenie konwertera grafiki na mapy myśli i algorytmów oraz stworzenie programu do uczenia maszynowego pozwalającego wyłuskać z tekstowych big data procedury do zapisania ich w algorytmach. Powstaną gotowe “cegiełki” do implementacji w projektowaniu nowych urządzeń. Może nastąpić gwałtowne przyspieszenie w rozwoju innowacji technologicznych.
Ktoś może zapytać, dlaczego dzielę się bezpłatnie pomysłami być może wartymi miliardy dolarów. Po prostu nie mam kapitału i zespołu, który podążyłby za moją wizją. Może znajdą się ludzie z podobną wizją, których zainspirują moje pomysły i wprowadzą je w życie. Nikt nie jest samotną wyspą. Współpraca przynosi najlepsze rezultaty.
Powyżej link do nagranego wywiadu na YouTube “Rewolucja informacyjna”
Piotr Michalak opublikował swój pomysł na rewolucję w wyszukiwaniu danych. Czy jego pomysł idzie w tym samym kierunku co mój pomysł dotyczący Globalnej Dynamicznej Mapy Myśli i Algorytmów oraz Web Pl 3.0. Może porównacie? Moim zdaniem projekt zmierza ścieżką edukacyjną (może być łatwo pokonany przez sztuczna inteligencję – w tym – głębokie uczenie), mój zaś idzie znacznie dalej w kierunku nowego typu elastycznej i ciągle aktualizowanej wyszukiwarki wiedzy generującej projektowe listy to do (nie tak jak Google, które szuka “tylko” informacji). Moje rozwiązanie daje możliwość stworzenia nowego globalnego pokolenia eksperckiego .
Z wywiadu można odnieść wrażenie, że niektórzy informatycy uważają starszych (po 50-tce) lekarzy za wykluczonych cyfrowo, którzy nie potrafią sobie poradzić z e-marketingiem, a przez to nie zarabiają na wiedzy. Być może jest inna tego przyczyna. Obecnie jest tak wiele literatury fachowej (często bezpłatnej), że nie będzie zapotrzebowania na płatne informacje zbiorcze, które codziennie się deaktualizują. Przygotowanie dobrego opracowania problemu medycznego do druku może zając od kilku do kilkudziesięciu godzin. Motywacja społeczna raczej nie wystarczy, aby taką pracę wykonać. Osobiście poświęcam na trudny przypadek minimum 10 godzin, bywa, że 30. Kolejną przeszkodą w takim projekcie jest szybko rozwijająca się sztuczna inteligencja. Być może algorytmy wyszukiwania w big data same przygotują takie raporty jak ma to miejsce w superkomputerze Watson IBM.
Co do wykluczenia cyfrowego starszych lekarzy mogę mówić za siebie. Kiedy nie było jeszcze w Polsce Internetu miałem już spółkę, która kontaktowała ze sobą sprzedających z kupującymi (Allegro powstało ponad 10 lat później, bo w 1999 r). Możliwe to było dzięki bazie danych na moim PC o dysku z pamięcią 20 MB 🙂 napisanej przeze mnie w programie dBase. Niestety wykorzystanie poczty i telefonów spowodowało, że musiałem zarzucić projekt. Nie był to jednak koniec z cyfryzacją w medycynie. Gdy niektórzy z dzisiejszych informatycznych CEO szli do pierwszej klasy szkoły podstawowej napisałem rozprawę doktorska na komputerze (wtedy większość prac pisana maszynie do pisania), korzystając z bazy w odpowiedniku dzisiejszego Excel zawierająca 12 tysięcy wyników badań. Jako jeden z pierwszych w Polsce wykorzystałem komputerowy program statystyczny do opracowania wyników mojej rozprawy. Wykonanie tak olbrzymiej pracy, dzięki komputerom zajęło mi dwa lata, gdy w tym czasie był to proces minim 4-5 letni.
Czy w Polsce nie ma lekarzy obejmujących kompleksowo problem pacjenta? Nie jest to prawdą. Mamy wprawdzie niewiele ośrodków chorób rzadkich, ale trzeba tylko wiedzieć o ich istnieniu. Rzeczywiście postęp medycyny i odgórne regulacje rozczłonkowały lekarzy na specjalistów w wąskich grupach wiedzy medycznej. W wielu przypadkach kodeks etyki lekarskiej nie pozwala udzielanie porad spoza swoje specjalizacji. Może to powodować zaszufladkowanie objawów chorego pod katem jednego specjalisty, gdy choroba ma lokalizację wielonarządową. W system NFZ trudno jest wówczas o rozszerzona diagnostykę. Jeśli lekarz ma obowiązek udzielić porady w ciągu 10-15 minut, nie ma możliwości w czasie takich przyjęć przeanalizować wszystkich opcji diagnostycznych.osobiści świadcząc usługę spersonalizowanej potrzebuję na takie podejście (włącznie z przeglądem piśmiennictwa naukowego) minimum 10 godzin. Jeśli chciałoby się więcej takich lekarzy – to usługa diagnostyki trudnych przypadków powinna kosztować pacjenta minimum = 2 (pacjentów/godzinę) x150 zł x10 godzin = 3000 zł. Niestety niewielu pacjentów byłoby w stanie (nawet mentalnie – mimo, że wydadzą te pieniądze chodząc latami od specjalisty do specjalisty) zapłacić za taką usługę. NFZ płacąc około 30 zł za wizytę pacjenta, chyba też nie będzie zainteresowany. Podobnie jest z dużymi, abonamentowymi spółkami medycznymi (liczy się ilość i obrót). Dlatego nie można mówić, że w Polsce nie ma lekarzy, którzy są stanie diagnozować kompleksowo. Wręcz przeciwnie jest wielu zdolnych i inteligentnych lekarzy. W Polsce natomiast nie ma tylu pacjentów, którzy są skłonni zapłacić godziwe wynagrodzenie za niestandardową pracę. Zostają więc tylko pasjonaci, którzy podejmują się tego trudnego zadania z symboliczne wynagrodzenie.
Niestety zawód lekarza nakłada na nas wiele ograniczeń etycznych (szczególnie w reklamie), dlatego też nie wykorzystałem programów typu Netmailer, Netsaler, które kupiłem już w 2011 r.
Następna uwaga do wywiadu. Czy wpisów lekarzy na blogach nikt nie czyta? Czy starszy lekarz nie ma pojęcia o socialmediach? Być może? Chyba, że liczba polubień mojego fanpage na Facebooku “Trudne przypadki medyczne – diagnostyka” mówi o czymś innym.
W wywiadzie dla Phila Konicznego pokazano ciekawą formę finansowania projektu – pewna forma crowdfunding ale poprzez blockchain – TOKENIZACJA (Ciekawe! Do rozważenia! przez potencjalnych inwestorów).
Problemy dzisiejszego internetu chaos informacyjny Piotr Michalak Rozmowy Konieczne #22
1-11-2020 – Moje uwagi do w/w projektu ccFound.
Nie znam całości i szczegółów tego rozwiązania, dlatego oprę się tylko na moim wrażeniu z dostępnych mi informacji.
Autorzy projektu przez kilka tygodni nie znaleźli czasu na odpowiedź na moją propozycję wspólnej pracy nad tym rozwiązaniem, szkoda (może ich strata).
Nie będę się wypowiadał o komercyjnej dla inwestorów stronie rozwiązania opartej na tokenizacji. Interesuje mnie tylko rozwiązanie technologiczne
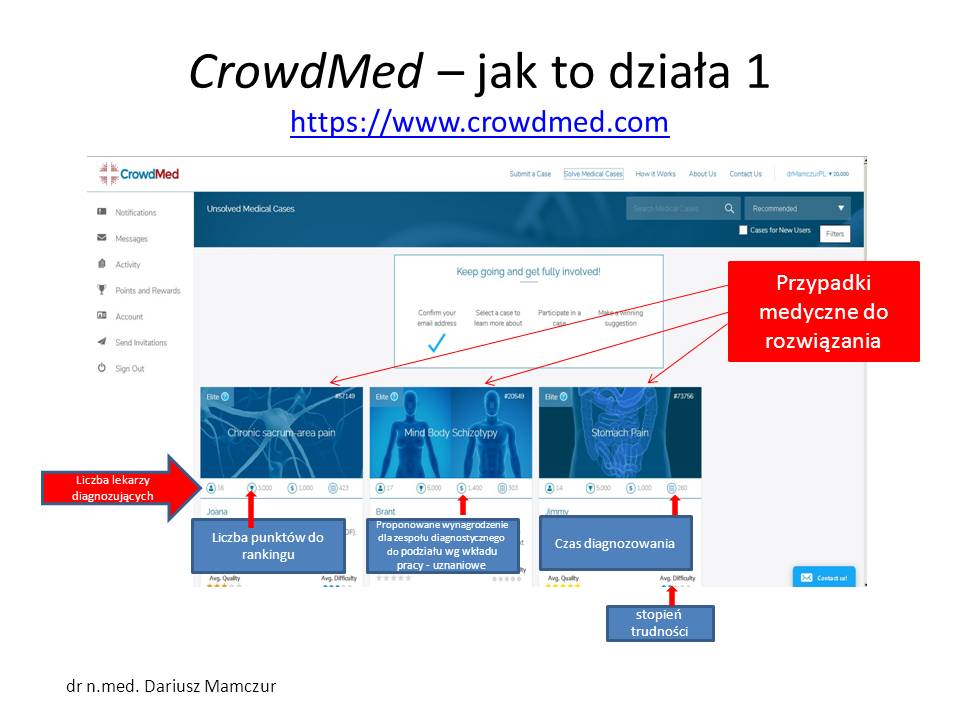
Oto model zachęcający lekarzy do współpracy z portalem CrowdMed
Myślę, że powielenie takiego serwisu dla polskich pacjentów nie powinno dla mnie stanowić problemu.
Moje uwagi powstały dzięki inspiracji MR (Pan po studiach informatycznych, który studiuje teraz medycynę – podziwiam otwartość na świat młodych ludzi).
Mentalnie projekt jest na etapie pierwszego dwudziestolecia XXI wieku. Opiera się na kombinacji Google (zawsze może być zbanowane, jeśli Google dostarczy swoje algorytmy, to nie będzie promował konkurencji za darmo), Quora (mieszanina społeczności i wolontariuszy – może zadziałać, ale to będzie tylko margines informacji, które dostarczy nowa technologia), Facebooka i Wikipedii (WIKI HOW).
Niestety automatyka procesów sztucznej inteligencji dostarcza już lepszych narzędzi do zdobywania wiedzy i to w zautomatyzowany sposób. Zaczyna dominować sztuczna inteligencja pod wieloma aspektami.
Dla przykładu proszę zauważyć dostarczanie przez Google z automatu najlepszych algorytmów rozwiązań, o które pyta czytelnik (oczywiście w uzupełnieniem w tradycyjny sposób o informacje. W ten sposób mamy ciągle aktualne rady (algorytmy), jakie możemy wyszukać w internecie. Nie trzeba za nic płacić, nie trzeba angażować do tego piszących na zamówienie artykułów ekspertów. takie rozwiązanie może oczywiście spowodować niechęć ekspertów do publikowania swojej wiedzy w internecie, ale jest już za późno – Google już ma dużą bazę do udzielania porad i to w różnych językach dzięki Tłumaczowi Google.
Oto ta dwa przykłady (dzięki uprzejmości MR- to on przekierował moje myslenia na współpracę z AI)
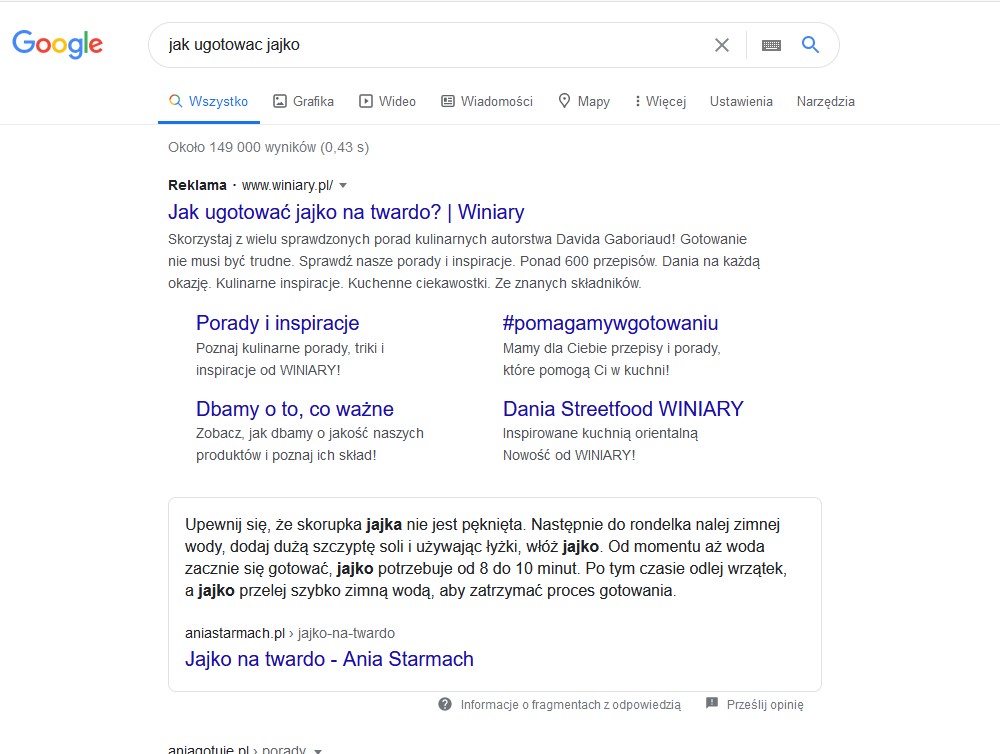
Jak ugotować jak jajko?– – wyszukany najlepszy (wg Google algorytm) na szczycie pozycjonowania
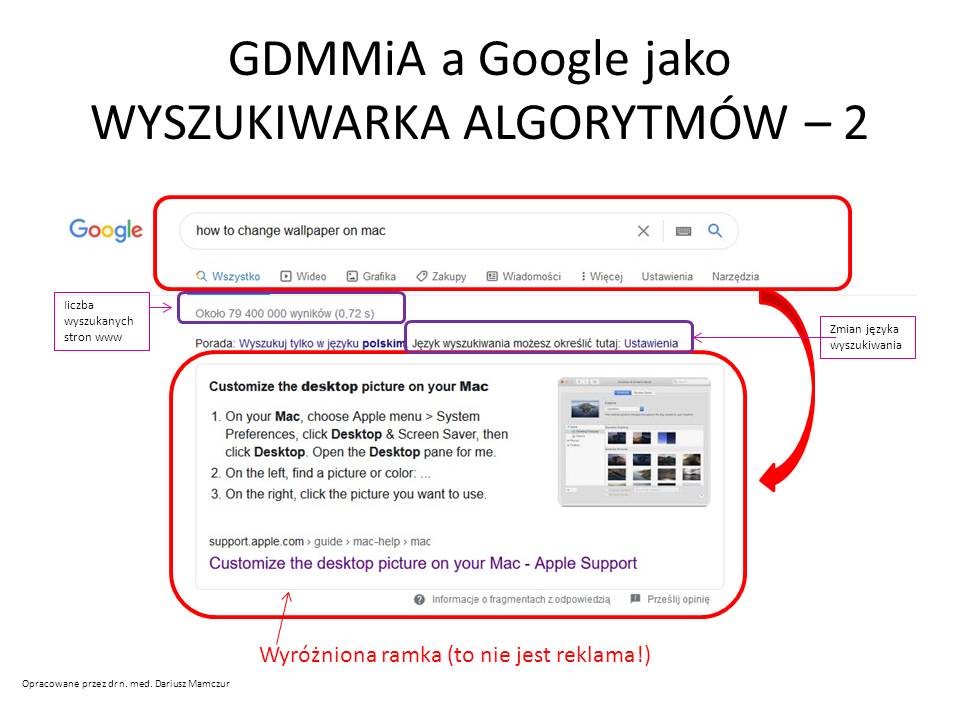
Inny przykład wyszukiwania algorytmów i zmiany języka wyszukanych informacji
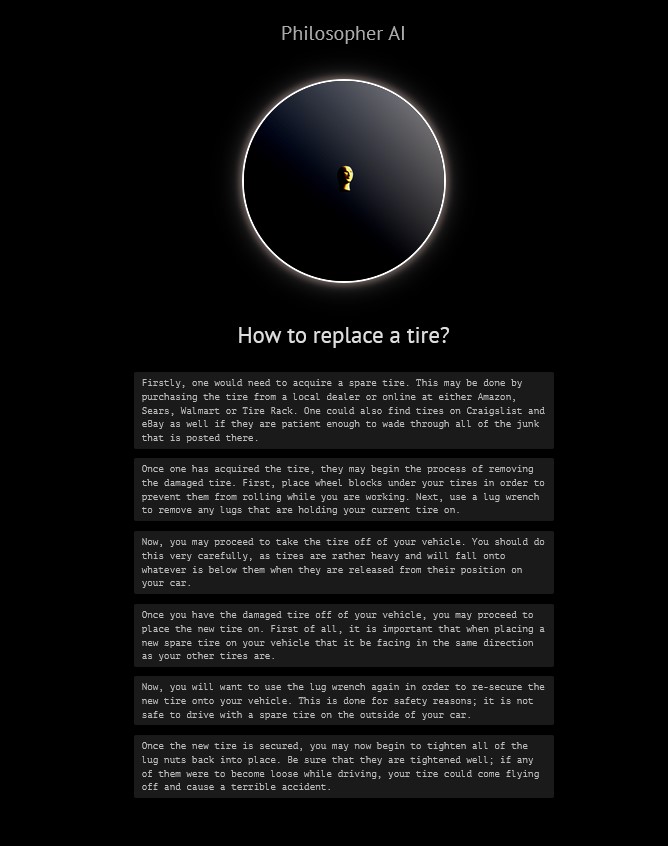
Zamiast artykułów na zamówienie Microsoft uznał, że programy oparte na GPT-3 (licencja na wyłączność Open AI -Elon Musk – dla Microsoft) (typu Philospher) zrobią to lepiej, wykorzystując naturalny język człowieka oraz korzystając z wyszukanej wiedzy w Internecie. Podobno zwolniono około 80 redaktorów piszących artykuły naukowe dla Microsoft. Oto jak sztuczna inteligencja odpowiada na pytanie jak zmienić koło w samochodzie (dzięki uprzejmości MR).
Nie ma co się dziwić, że nikt nie robi tego co chce wykonać ccFound, robią coś na wyższym poziomie technologicznym.
Inna epoka, inne myślenie, inne narzędzie – chociaż cel jest ten ciągle sam – dostarczyć wszystkim ludziom wiedzę i mądrość działania.
Ma on być wykorzystywany m.in. do badań z zakresu epidemiologii, energetyki, cyfrowej medycyny czy projektowania nowych materiałów.
“Dzięki superkomputerowi, obliczenia o wysokiej wydajności (HPC – High Performance Computing), będą rozszerzone o zadania sztucznej inteligencji (AI – Artificial Intelligence) i wysokowydajnej analizy danych (HPDA – High Performance Data Analytics). Cato umożliwia modelowanie i symulacje w oparciu o zbiory dużych danych.”
W medycynie: “Wykorzystanie globalnych zasobów danych w sposób inteligentny do podejmowania decyzji diagnostycznych, a następnie sugestii terapeutycznych, jest dziś warunkiem koniecznym rozwoju medycyny” – ocenił prof. Niezgódka. Wyjaśnił, że dzięki metodom obliczeniowym można wypracowywać precyzyjne metody diagnostyczne dostosowane do danych konkretnego człowieka, ale wykorzystujące wiedzę w skali globalnej.”
Ponadto możliwe będzie projektowanie nowych materiałów (np. medycznych) i ich weryfikacja przy pomocy symulacji komputerowych.
Według Narodowy Instytut Zdrowia Publicznego – Państwowego Zakładu Higieny
(Zakład Epidemiologii Chorób Zakaźnych i Nadzoru – “Choroby zakaźne i zatrucia w Polsce” (biuletyn roczny za 2018 r) w Polsce odnotowano w 2017 r. 30 przypadków a w 2018 r. – 17 nowych zachorowań na tularemię (A21). Jest to choroba zakaźna objęta obowiązkiem zgłaszana do PSSE. Czy mała ilość zgłoszeń spowodowana jest niewielka liczbą zachorowań, czy też choroba jest mało znana przez lekarzy (szczególnie jako tzw. choroba odkleszczowa – bo – boreliozę zna każdy), czy też rzadko zleca się testy diagnostyczne? Trzeba zauważyć, że popularne obecne testy przesiewowe w kierunku chorób odkleszczowych nie obejmują tularemii!!.
Choroba chyba należy do tych, które, aby je znaleźć, trzeba wiedzieć, czego się szuka (podobnie jak w chorobach genetycznych, chlamydiozach czy gruźlicy). Nie wystarczy zlecić podstawowe badania. Trzeba wiedzieć, jakie testy należy wykonać. Poza tym wiele laboratoriów nie wykonuje takich analiz.
Tularmię (zwaną też “gorączką zajęczą) brałem pod uwagę w rozpoznaniu różnicowym u mojego pacjenta cierpiącego od roku na nietypowe zmiany w jamie ustnej. Wczoraj otrzymałem dodatnie wyniki przeciwciał p-ko tularemii w klasach IgA, IgM i niewielkie w klasie IgG. Poinformowałem o tym PSSE. Chory został poproszony o pilne zgłoszenie się do lekarza chorób zakaźnych. Obraz choroby u tego pacjenta może być zamazany, ponieważ chory już wcześniej od innych lekarzy otrzymywał antybiotyki o szerokim spektrum działania. Niestety leczenie tularemii wymaga stosowania odpowiedniego leku i to długo, bo przez 14-21 dni. Zwykle są to grupy antybiotyków o większej liczbie objawów ubocznych. Dlatego też przed włączeniem leczenia powinno się uzyskać potwierdzenie choroby badaniami mikrobiologicznymi (Uwaga trzeba uprzedzać laboratoria o materiale zakaźnym!) lub badaniem PCR – prawdopodobnie wykonuje to badanie laboratorium PZH w Warszawie. (Osoba kontaktowa: prof. dr hab. Aleksandra Zasada, mgr Kamila Formińska. Tel. 22 5421263
“Tularemia jest przenoszona bezpośrednio i pośrednio przez wodę, pokarmy, powietrze, kleszcze i niektóre stawonogi. W Europie Centralnej nosicielem Francisella tularensis są kleszcze z rodzaju Dermacentor reticulatus i Ixodes ricinus. Rezerwuarem zarazka są małe gryzonie, myszy, szczury, wiewiórki, zające, króliki, lisy, zwierzęta domowe oraz stawonogi odżywiające się krwią. Człowiek zaraża się przez ukłucie zakażonych stawonogów np. kleszczy, poprzez kontakt bezpośredni (skóra, błony śluzowe), drogą pokarmową i wziewną. Tularemia nie przenosi się bezpośrednio z człowieka na człowieka. W miejscu wniknięcia pojawia się naciek lub rumień guzowaty. Bakterie dostają się do różnych narządów: wątroby, śledziony, płuc, opłucnej, nerek, węzłów chłonnych”
Do zakażenia ludzi dochodzi teżukąszenia tzw. latających kleszczy (tj. much jelenich = strzyżak jeleni)
Taką muchę miałem nieprzyjemność “gościć” na swojej ręce (zdjęcie obok- przepraszam za ostrość – wielkość “kleszcza kilka milimetrów) po spacerze (2020) w lesie niedaleko Łodzi (Żabiczki koło Konstantynowa Łódzkiego). Muchy jelenie (strzyżak jeleni) latają dużymi grupami. Zaraz po dotarciu do ofiary tracą skrzydła). Czyli uwaga “muchy” w lesie!
Osobnym potencjalnym sposobem ekspozycji jest bioterroryzm ze względu na małą liczbę (10-50) bakterii konieczną do wywołania choroby. Bakterie mogą wnikać do organizmu człowieka przez skórę, oczy, jamę ustną lub płuca.” “Nie opisano żadnego przypadku transmisji zakażenia z człowieka na człowieka. Epidemie tularemii rozwijały się w przeszłości na przykład za pośrednictwem chomików zakupionych w sklepach zoologicznych..”
W lutym 2020 opisałem pacjenta (ojciec Hiszpan, mama Polka), u którego podejrzewałem chorobę, która może mieć związek z początkowym okresem życia chłopca w Hiszpanii.
Rozważałem m. in. choroby genetyczne i choroby pasożytnicze.
W rodzinie ojca było kilka przedwczesnych zgonów z niejasnych przyczyn.
U chłopca wykluczono choroby tropikalne. Pani doktor pediatra-nefrolog z wiodącego szpitala w Polsce zleciła test WES, który wykazał obecność rzadkiej mutacji, odpowiedzialnej m. in. za wrodzoną kardiomiopatię rozstrzeniową. Matka chłopca nie ma takiej mutacji. Być może hiszpańska rodzina chłopca pozna tajemnicę wczesnych zgonów swoich krewnych. Jeśli podobnych zgonów w tej okolicy było więcej, to być może mutacja jest bardziej rozpowszechniona. W takiej sytuacji hiszpańska służba zdrowia powinna wykonać badania przesiewowe w kierunku tej mutacji. Jeśli takich przypadków będzie więcej istnieje szansa na badania kliniczne nad leczeniem enzymatycznym?
Ta strona używa plików cookie. Korzystając z niej zgadzasz się na ich przyjmowanie. Dowiedz się więcej lub kontynuuj. ZamknijDowiedz się wiecej
Polityka prywatności
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.





 (
(