
Rozwijająca się w ostatnim czasie w bardzo w szybkim tempie sztuczna inteligencja wymaga dostarczani jej dużej ilości algorytmów. Z czasem będzie możliwe szerokie stosowanie uczenia maszynowego, które te algorytmy będzie tworzyć samodzielnie. Zalążek takich programów zależy jednak od wiedzy twórców danych innowacji. To oni tworzą algorytm – czasem lepszy, czasem gorszy. Potem, owszem, można przeprowadzać komputerowe badania modelowe, ale badamy tylko koncepcję jednego zespołu. A co by było, gdyby mogli oni skorzystać z już zweryfikowanych algorytmów z innej części świata? Ilu błędów by uniknięto? Jakich pomysłów nie byłoby w burzach mózgów ich zespołów, a są w GMMiA ? Na następnym etapie baza algorytmów byłaby “pożywką” dla komputerów, które dzięki sztucznej inteligencji (w tym głębokiego i maszynowego uczenia) mogłaby tworzyć nowy, bardziej kreatywny algorytm, o którym ludziom się nawet nie śniło (tak jak rewelacyjny ruch nr 37 w grze GO podczas meczu Lee Sedol z komputerem Google – AlphaGo).
Uważam, że koncepcja Globalnej Dynamicznej Mapy Myśli i Algorytmów (GDMMiA) mogłaby się sprawdzić w tym procesie.
Mapy algorytmów w etapie wstępnym można tworzyć ręcznie (przez ogólnoświatową społeczność – zalążkiem ich byłyby mapy myśli), można też zaimportować pliki graficzne map myśli z dotychczasowych książek, publikacji internetowych ( potrzebny by był program konwertujący grafikę do map algorytmów – nie znalazłem nigdzie takiej aplikacji) – z nich powstaną listy “to do” dla prototypów wynalazków.
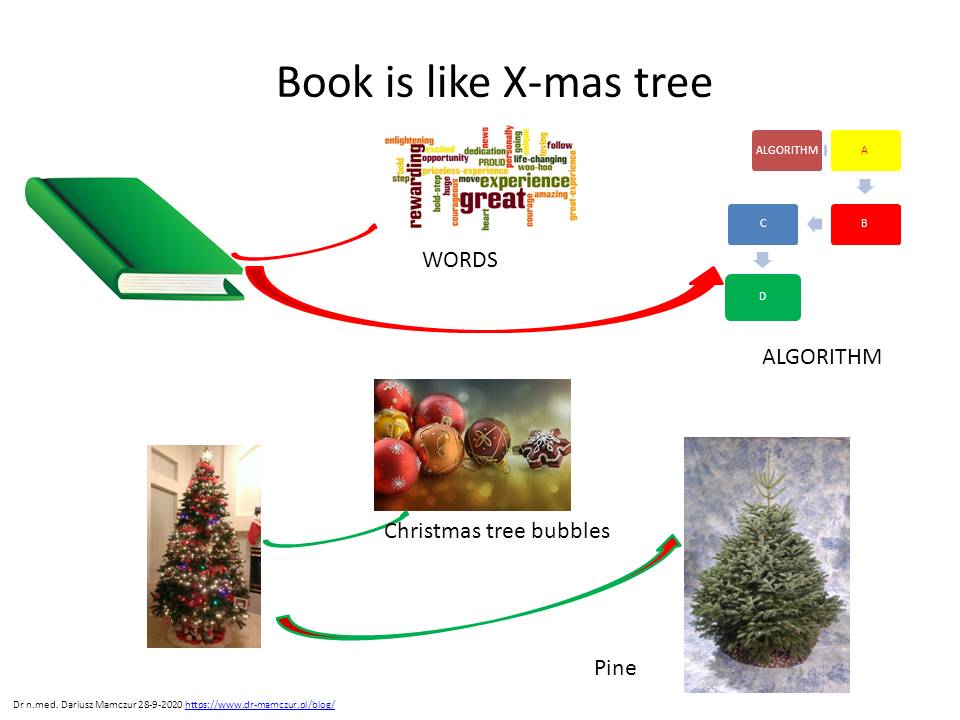
Problemem jest jednak jak przełożyć dotychczasową wiedzę tekstową na algorytmy. Myślę, że z pomocą może przyjść uczenie maszynowe pracujące na big data. Być może wyszukiwarki semantyczne mogłyby wchodzić w skład silnika takiej aplikacji. Narzędzie to po analizie tekstu, stworzy algorytm podsumowujący treść danej publikacji. Algorytmu się nie oszuka!. Jeśli jest on taki sam jak w innej książce opisującej innymi słowami tę samą procedurę – od razu będzie widać, że autor książki nie wniósł nic nowego dla ludzkości (zobaczmy ile jest poradników sprzedających te same porady, ale tylko innymi słowami. Ile cennego czasu tracimy na czytanie tego samego pod innym tytułem – i to tego samego autora). Z książkami jest jak z choinką. Jest algorytm ubrany w słowa, tak jak sosna ubrana w bąbki.
Choinkę możemy ubierać w różne bąbki, ale zawsze będzie to ta sama choinka.
 Ponadto uczenie maszynowe pozwoliłoby na ciągłą, zautomatyzowaną (dynamiczną) aktualizację bazy, przy współistniejącej dotychczas formie werbalnej i graficznej przedstawiania swoich myśli (książki, strony www, grafiki, zdjęcia).
Ponadto uczenie maszynowe pozwoliłoby na ciągłą, zautomatyzowaną (dynamiczną) aktualizację bazy, przy współistniejącej dotychczas formie werbalnej i graficznej przedstawiania swoich myśli (książki, strony www, grafiki, zdjęcia).
To jest zupełnie inny silnik niż Google!!
Prawdopodobnie nikt takiego nie ma!!.
To nie internauta w tym narzędziu przeszukuje bazy danych. On dostaje już gotowe zaktualizowane rozwiązania (wiedzę – ekspertyzę) na swoje zapytanie. Zostaje mu jedynie jej przeanalizowanie i zaimplementowanie jej dla swoich potrzeb i podzielenie się zdobytą w ten sposób wiedzą nią z innymi (utopia – czy potrzeba czasu). Rzetelność, stabilność systemu i prawa autorskie mógłby zagwarantować blockchain.
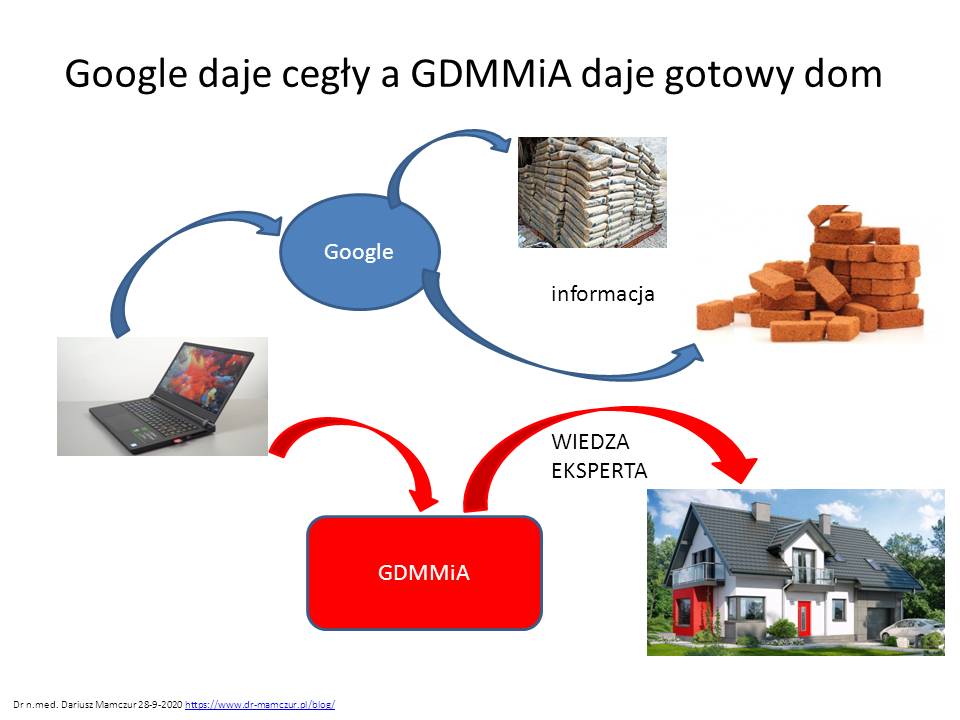
Google daje nam cegły i cement (tylko informacje – WAT?) , mój silnik od razu gotowy dom (daje wiedzę eksperta – HOW!). Czyli bardziej zaawansowane narzędzie niż robione “ręcznie” WIKI-HOW.
Dlatego uważam, że w najbliższym czasie w realizacji GDMMiA najcenniejsze może być stworzenie konwertera grafiki na mapy myśli i algorytmów oraz stworzenie programu do uczenia maszynowego pozwalającego wyłuskać z tekstowych big data procedury do zapisania ich w algorytmach. Powstaną gotowe “cegiełki” do implementacji w projektowaniu nowych urządzeń. Może nastąpić gwałtowne przyspieszenie w rozwoju innowacji technologicznych.
Ktoś może zapytać, dlaczego dzielę się bezpłatnie pomysłami być może wartymi miliardy dolarów. Po prostu nie mam kapitału i zespołu, który podążyłby za moją wizją. Może znajdą się ludzie z podobną wizją, których zainspirują moje pomysły i wprowadzą je w życie. Nikt nie jest samotną wyspą. Współpraca przynosi najlepsze rezultaty.